Sidebar
 Add this page to your book
Add this page to your book  Remove this page from your book
Remove this page from your book  Manage book (
Manage book ( Help
Help Table of Contents
4.1. 統計的予測
GMDH Streamlineは、時系列分解と間欠需要モデルと各品目に適切なモデルを選択する人間に近い意思決定アルゴリズムを利用します。一般的に、モデルの過剰適合はモデルを過度に複雑化し、モデルの極端な単純化はデータの依存関係を表せなくなります。あてはめと単純化のバランスが重要で、GMDH Streamlineのアプローチは、モデルの過剰なあてはめに高い耐性があります。このアプローチのおかげで、不規則な需要への過剰適合をせずに、季節性やトレンドや水準の変化などの、実際のデータの依存関係をすべてとらえることができます。正確な予測を作成するための唯一の方法は、データの依存関係をとらえることであり、これを表す最も単純なモデルを選択することが、GMDH Streamlineの目標です。モデルあてはめとモデルの単純化のバランスは難しいですが、GMDH Streamlineではこれを実現し、最終的に最大限の高い精度が結果となります。
他のツールと比較方法
市場には数多くの需要予測ツールがありますが、GMDH Streamlineは、需要の統計的予測をするために、わずか2つの方法に従っています。時系列分解方法と最良モデル選択方法です。時系列分解方法は、(他のツールよりも少し賢いアルゴリズムがいくつかあり)データの傾向を理解するために利用されます。最良モデル選択方法は、一番当てはまりの良いモデルを選択するために利用されます。残念ながら、最良モデル選択方法のアプローチは、過去の需要からの潜在するパターンを見つけ出すことに関心がありません。GMDH Streamlineと同様に、市場をけん引するベンダーのほとんどが、詳細な時系列分解を実装ずみですが、その一方で、モデルの過剰適合を招く一昔前の最良モデルの選択方法を採用する時代遅れのベンダーもいます。このことに注意してください。
時系列分解
需要データの分析は、先行注文に起因するスパイク1)の除去、欠品や祝日を考慮した調整、予測に関連する履歴の長さを検出するから始まります。その後、需要を水準とトレンドと季節性に分解します。
時系列モデルの数式は、(傾き * 回数 + 水準) * 季節性 * 調整値 です。
上記の時系列モデルの構成要素には、傾きと水準と季節性があります。説明した時系列モデルだけではなく、その構成要素の組み合わせも、時系列モデルになります。そこで、説明した時系列モデルと構成要素からなる時系列モデルの2つを合わせ、時系列モデルのサブセットと考えることができます。GMDH Streamlineは、各計画品目に対して時系列モデルのサブセット中から有効なモデルを自動的に決定します。決定されたモデルは、単なる水準となる可能性もあります、また水準 * 季節性や(傾き * 回数 + 水準) となる可能性もあります。自動決定されたモデルだけではなく、ユーザーがモデルを指定をすることもできます。
次の例から、一定水準モデルと、線形トレンドモデルや季節性とトレンドモデルの違いがわかります。2)。:
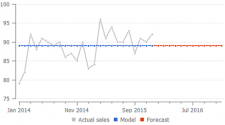
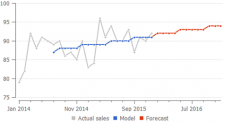

予測に関連する履歴の長さを検出する
GMDH Streamlineの “秘伝のたれ” は、予測に関連する履歴の長さを検出するアルゴリズムにあり、このアルゴリズムからモデルのトレンド成分を推定します。一方で、季節係数の計算は、0以外の販売履歴をすべての利用します。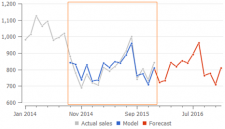
品目の立ち上げ時のデータや単に非常に古い販売データは、現在のビジネス状況とは関連がなく、誤った予測を招く計画となります。この場合、GMDH Streamlineは、モデルに適合する期間を短縮し、データの適切な部分だけからトレンドを捕まえます。右のプロット表示例は、GMDH Streamlineがオレンジ色の四角内のデータだけを利用して、トレンドパラメータを計算します。
外れ値の除去
信頼性の少ないデータの読み飛ばし
欠品日数が70%より多い期間は、データの信頼性が少ない期間と判断されます。品目の予測の立案時にこれらの期間のデータは考慮されません。
欠品があった期間の需要調整
ある期間中に欠品があり、さらにその期間中の欠品日数の割合が70%未満の場合、モデル作成前に期間中の需要は欠品日数の割合で調整されます。例えば、期間中に30%の欠品日数がある場合、需要は調整され、調整後の需要は 実際の需要 / 0.7 になります。
間欠需要モデル
間欠需要モデルは、多くの期間で需要がなく、需要が明らかにランダムである場合に適用されます。この需要パターンは、でこぼこ、不規則、ランダム、または、バラバラと呼ばれることがあります。
間欠需要モデルには対数正規分布が適用され、対数正規分布の需要発生の確率、需要の中央値、偏差が計算されます。平均需要は、適切な安全在庫水準をもとにしますが、常に0と等しくなります。